Learning Transferable Visual Models From Natural Language Supervision
Radford et al., 2021
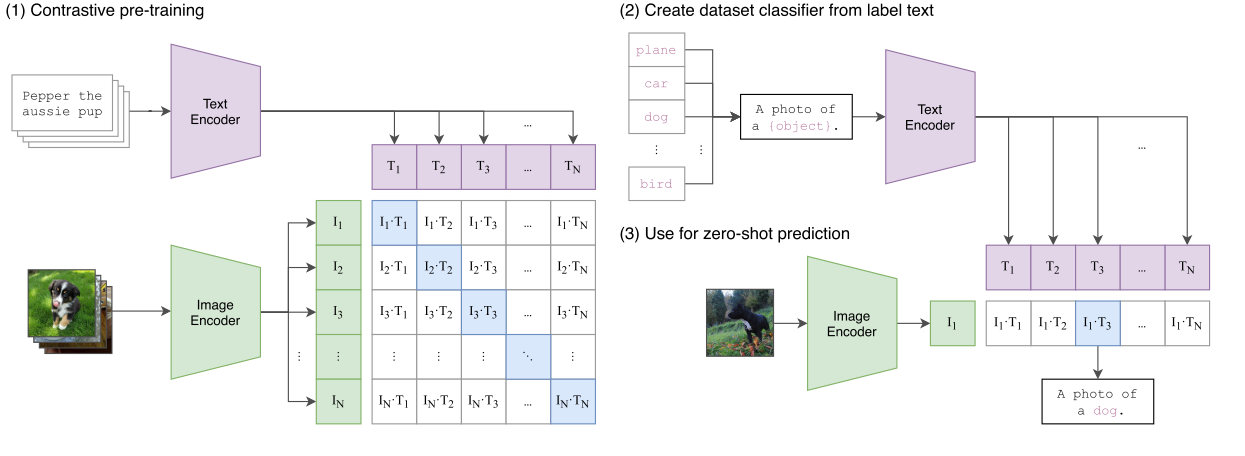 Source: Radford et al., 2021
Source: Radford et al., 2021Summary
- Most computer vision systems have a fixed, predetermined output limiting their ability to perform zero-shot transfer
- Zero-shot transfer performance has not been great on complex tasks (e.g. ImageNet)
- Use large-scale natural language supervision (400 million examples) to facilitate zero-shot transfer
- Able to match performance of ResNet-50 on ImageNet zero-shot, as well as on many other datasets
- Zero-shot CLIP models are more robust than supervised ImageNet models of equivalent accuracy
- Links: [ pdf ]
Background
- Within NLP, recent results demonstrate that supervision on web-scale collections of text surpasses that of high-quality, crowd-labeled datasets
- However, scalable pre-training methods in computer vision have not yet reached competitive performance – largely due to a lack of scale
- Previous work used either MS-COCO (~100,000 training images), Visual Genome (also small), or YFCC100M (sparse and variable quality metadata)
- Contrastive Language-Image Pre-training (CLIP) efficiently learns from natural language supervision on a dataset of 400 million (image, text) pairs
- Motivated by the idea of learning perception from supervision contained within natural language
Methods
- Creating sufficiently large dataset, WebImageText (WIT): similar total word count as WebText, which was used to train GPT-2
- Search for (image, text) pairs whose text includes one of 500,000 queries
- Efficient pre-training method: use contrastive objective instead of predictive objective
- Given batch of $N$ (image, text) pairs, trained to predict which of the $N \times N$ pairs actually occurred
- Train from scratch, with linear projection from each encoder to the multi-modal embedding space
- Only use random crop for data augmentation
- Choosing and scaling a model:
- Use modified ResNet-50 or ViT for image encoder and Transormer for text encoder
- Scale image encoder along width, depth, and resolution and text encoder along only width
- For best model, pre-train at higher 336 pixel resolution for an additional epoch (similar to FixRes)
Results
- Zero-shot Transfer with CLIP: For each dataset, predict most probable (image, text) pair using text generated from class names
- Text encoder can be viewed as hypernetwork that generates weights of a linear classifier, on top of the image encoding, using the text
- Improves ImageNet accuracy from 11.5% by Visual N-Grams to 76.2%, matching original ResNet-50
- Using prompt template, e.g. “A photo of a {label}.”, improves performance by a couple percentage points, and ensembling prompts provides additional gains
- On 16 out of 27 datasets zero-shot CLIP outperforms linear probe on pre-trained ResNet-50
- CLIP does poorly on specialized, complex, or abstract datasets (e.g. satellite images, tumors, synthetic scenes)
- Zero-shot transfer efficiency varies from 1 labeled example per class to 184 across the datasets
- Evaluating on natural distribution shifts: ImageNetV2, ImageNet Sketch, ImageNet-Vid, ObjectNet, ImageNet Adversarial, ImageNet Rendition
- ResNet-101 makes 5 times as many mistakes on these natural distribution shifts
- Zero-shot CLIP improves robustness to distribution shift, reducing the gap by up to 75%
Conclusion
- CLIP’s zero-shot performance still weak on some tasks, where data is truly out-of-distribution
- Still limited to only choosing fixed set of concepts, versus a more flexible approach like generating image captions
- Still uses a lot of data (400 million examples), although acquiring it is relatively cheap
- Training on unfiltered images and text from the internet results in the model learning many social biases