Humans, but Not Deep Neural Networks, Often Miss Giant Targets in Scenes
Eckstein et al., 2017
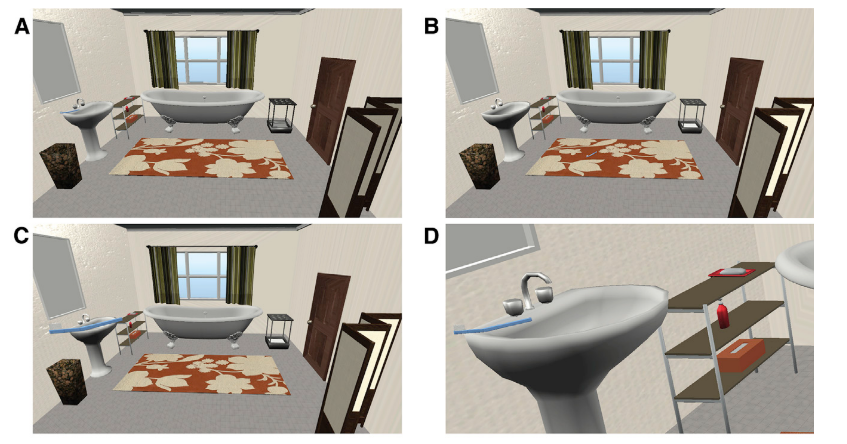 Source: Eckstein et al., 2017
Source: Eckstein et al., 2017Summary
- Investigate how humans use information about scenes to guide search towards likely target sizes
- Show that humans often miss missized targets, but not deep neural networks
- Human behavior is a result of a useful strategy for rapidly discounting potential distractors
- Links: [ website ]
Background
- Animals have an unmatched abilty to visually search complex scenes
- Humans rapidly process a scene, utilizing object relationships and global properties to efficiently guide search
- Hypothesize that scene information also guides search towards likely target sizes, in addition to locations
- If search is guided towards likely target sizes, mis-scaled targets would be missed more often, despite being larger
Methods
- 60 participants viewed 42 rendered scenes, each with unique target object
- 14 target objects, repeated 3 times with variations (color and viewing angle)
- Presented with word of target, then given 1s to search the scene
- Reported wethere target was present or not (50% of scenes contained target)
- Experimental conditions:
- One-third of scenes had targets consistent in size with the scene (normal)
- One-third where target was enlarged by a factor of 3-4x (mis-scaled)
- One-third where the scene was cropped and rescaled so the target matched the size in the mis-scaled condition (control)
Results
- The hit rate of humans was significantly lower when target was mis-scaled (~70%) compared to normal (~80%)
- Deficient for mis-scaled targets diminished in the last (of six) blocks
- Minimum distance between fovea and target was the same between normal and mis-scaled conditions, indicating that observers were foveating on the target in both cases
- Hit rate in control condition was almost perfect, indicating deficient in mis-scaled condition not due to feature-based changes
- Results remained the same when only considering mis-scaled target objects that observers could reliably classify
- Object detection DNNs (Faster R-CNN, R-FCN, YOLO) do not show reduced target probabilities when target is mis-scaled
- DNNs had similar target object probabilities when target was present and absent, possibly because they do not take size consistency into account
Conclusion
- Demonstrates that huamns use scene information to guide search towards likely target sizes, resulting in higher miss rates for mis-scaled targets, which does not occur for object detection DNNs
- Could be a result of humans using likely target size to rapidly filter out potential distractors
- Would be interesting if they also tested scaled-down targets, although correcting for feature-based effects might be more difficult
- How does human performance change with different search durations?
- Would DNNs better match human behavior if they were also trained to perform time-limited visual search?
- Also the DNNs tested were overall not great at detecting the objects, with target object probabilities under 50%