VisualCOMET: Reasoning about the Dynamic Context of a Still Image
Park et al., 2020
 Source: Park et al., 2020
Source: Park et al., 2020Summary
- Proposes VisualCOMET for visual commonsense reasoning, predicting possible past and future events and people’s present intents
- Introduce first large-scale repository of Visual Commonsense Graphs
- Demonstrates that integration between visual and textual reasoning outperforms non-integrative appraoches
- Links: [ website ] [ pdf ]
Background
- Given an image, humans can reason about the story underlying the scene
- Image captioning systems, while correct, fail to understand the dynamic situtation – making inferences beyond just what’s depicted
- This requires sophisticated knowledge about how the visual and social world works
- In contrast to work on visual future prediction, future events are compactly described using language
- Visual Commonsense Reasoning (VCR) tests use a question answering setup that makes it difficult to generate inferences
- Other previous work, e.g. ATOMIC, also tackled commonsense reasoning, but in a purely textual context
Methods
- Visual Commonsense Graphs contain:
- textual descriptions of events at present
- commonsense inferences on events before
- commonsense inferences on ** events after**
- commonsense inferences on people’s intents at present
- textual description of the place
- co-reference links (i.e. person grounding) between people in the image and people in the textual descriptions
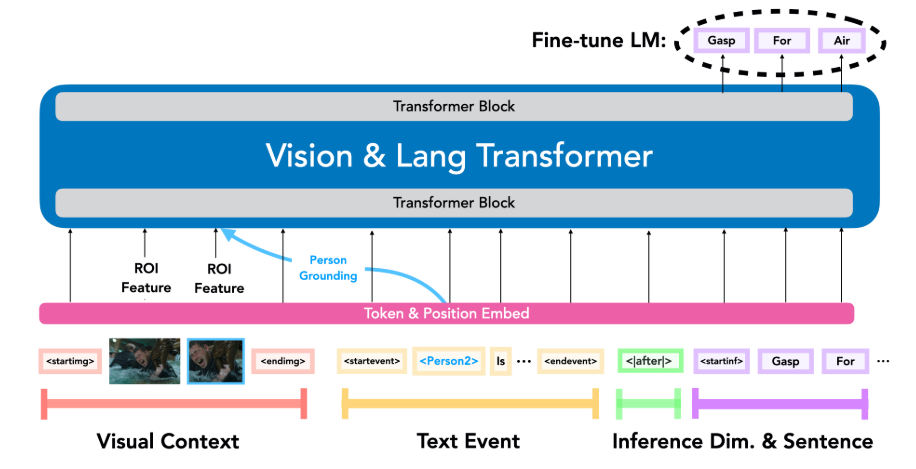
- VisualCOMET: takes a sequence of visual embeddings for the image and people in the image, event description, scene’s location description, and inference type and generates a set of possible inferences
- Visual features:
- Use RoI Align features for image and detected people
- Sum visual representation for a person with word embedding for the person token in the text (i.e person grounding)
- Text representation:
- Special tokens indicating start and end of image, event, place, and inference fields
- Use one of thre inference types (before, intent, after) as start token for generating inference statements
- Single stream vision-language transformer
- GPT-2
- Trained by minimizing negative log-likelihood over inference instances in dataset
- For models that do not take textual input (event and location), can also supervise with these using seq2seq loss (EP loss)
- Visual features:
Results
- Baselines based on ablations on inputs (place, event, image) and person grouding trick
- Metrics:
- Automatic Evaluation:
- Image captioning metrics: BLEU-2, METEOR, CIDER
- Acc@50: average accuracy of ground truth inference based on 50 candidates ranked with perplexity score
- Diversity: percent unique and percent novel
- Human Evaluation: humans asked to evaluate each inference is likely or unlikely to happen based on the image
- Automatic Evaluation:
- Results summary:
- Person grounding improves performance across all automatic metrics
- Model trained with both visual and textual input outperforms models trained with only one modality across all automatic metrics
- Adding EP loss improves performance when only the image is available at test time
- There is a 20% gap between the best model and ground truth inferences, and an even larger 40% gap for models without text input
- Inferences generated from the image only are sometimes wildy incorrect (with respect to the event description),
Conclusion
- The large-scale dataset of Visual Commonsense Graphs is valuable for future research on visual commonsense reasoning
- The mistakes by the image only models, e.g. mistaking a presentation with a bar or party, indicate that the visual features are still missing the level of visual understanding humans possess
- The large drop in performance on the quantitative metrics for these models also supports this
- While there are clear advantages to integrating visual and textual information, generating inferences from only images is a more realistic task