RELATE: Physically Plausible Multi-Object Scene Synthesis Using Structured Latent Spaces
Ehrhardt et al., 2020
 Source: Ehrhardt et al., 2020
Source: Ehrhardt et al., 2020Summary
- Presents RELATE, which learns to generate physically plausible scenes and videos of multiple interacting objects
- Combines an object-centric GAN with an explicit model of correlations between individual objects
- Learns a physically-interpretable parameterization that generate realistic videos and supports physical scene editing
- Links: [ website ] [ pdf ]
Background
- Image generation with GANs produce realistic images, but generally have parameterizations that are not interpretable
- Adding structure to the latent space gives partial physical interprtability
- E.g. BlockGAN, which incorporates concepts like position and orientation, but assumes objects are mutually independent
- RELATE leverages the architectural biases of BlockGAN to model correlations between latent object state variables
Methods
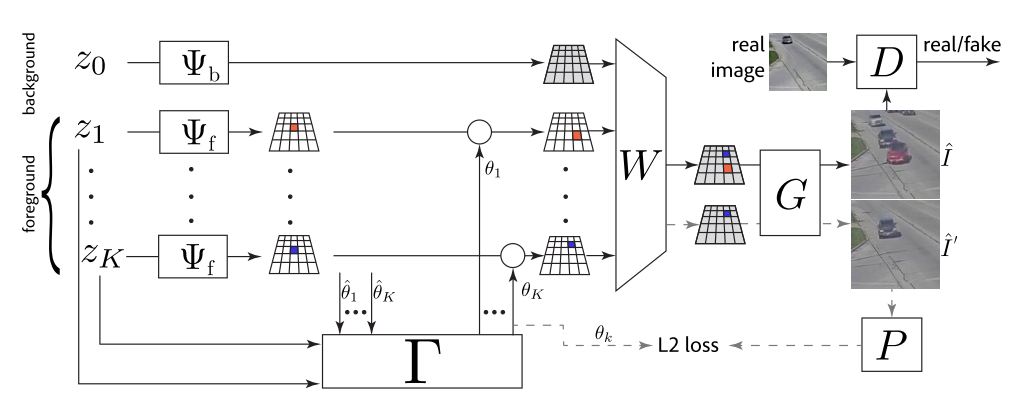
- Scene composition and rendering module:
- Starts by independently sampling random appearance parameters, $z_0, \ldots, z_K$, for $K$ objects in the scene and the background
- Map appearance parameters for objects and background to tenser $\Psi \in \mathbb{R}^{H \times H \times C}$, via two separate learned decoders
- Each foreground object also has a corresponding pose parameter $\theta_k \in \mathbb{R}^2$ which represents a 2D translation
- Foreground objects and background are composed into overall scene tensor via element-wise max pooling
- Final decoder network renders complete scene as an image
- Interaction module:
- Does not assume pose parameters are independent, unlike BlockGAN
- First sample a vector of $K$ i.i.d. poses
- Then pass this vector into a correction network, based on Neural Physics Engine, that remaps the initial configuration accounting for the correlation between object locations and appearances
- Apply same correction function to each object’s pose parameter in parallel, to enforce symmetry
- To make dynamic predictions, can learn object velocities using NPE style updates and use them to update pose parameters
- Learning objective is a combination of the GAN discriminator loss and style loss for the generated images, and $l_2$ loss of a position regressor network that predicts the location of objects given a generated image
Results
- Baselines:
- GENESIS: parameterises a spatial GMM over images which is decoded from a set of object-centric latent variables
- OCF: explicitly represents the 2D position and depth of each object, as well as an embedding of its segmentation mask and appearance
- Datasets:
- BallsInBowl: two balls in elliptical bowl
- CLEVR: cluttered tabletops
- ShapeStacks: block stacking
- RealTraffic: busy street intersection, with one to six cars
- Metrics:
- Frechet Inception Distance (FID): quantifies the similarity between the distribution of generated samples and real world samples
- Frechet Video Distance (FVD): considers distribution over videos to capture temporal coherence, in addition to quality of each frame
- Ablations:
- BlockGAN2D: removes spatial correlation module and position regression loss
- w/o residual: removes residual in pose correction network
- w/o pose. loss: removes position loss
- Each component of RELATE yields improvement in FID on BallsInBowl
- RELATE beats baselines on all datasets although BlockGAN2D is close on CLEVR-5 and ShapeStacks
- Scene editing to change the position or appearance of objects works to an extent, and can generate images with more/less objects than seen in training
- RELATE for modeling dynamics does better than time-shuffled baseline, but no strong baseline tested.
- Qualitative results are also hard to judge since dynamics are pretty simple and limited to 2D translations
Conclusion
- Cannot account for large changes in appearance, e.g. due to changes in perspective, since appearance parameters are fixed
- Size of objects and initial poses are artificially limited
- Although the pose parameter can be extended to 3D, it is unclear how well it will work in practice
- One possible concern could be the effect on the position regression loss, which was shown to be critical
- Provides a good starting point for learning dynamics from raw videos with structured, interpretable object-centric parameterization