On The Power of Curriculum Learning in Training Deep Networks
Hacohen and Weinshall, 2019
 Source: Hacohen and Weinshall, 2019
Source: Hacohen and Weinshall, 2019Summary
- Various, sometimes seemingly contradictory, methods for curriculum learning in CNNs have shown empirical benefits
- Analyzes the effect of curriculum learning by studying different scoring and pacing functions
- Provides theoretical evidence that curriculum learning changes the optimization landscape, but not the global minimum
- Links: [ website ] [ pdf ]
Background
- Taking inspiration from formal education, curriculums have been applied to DNNs
- The intuition is that presenting easier examples first helps the learner
- Creating a curriculum involves addressing two challenges
- Arranging the content in a way that reflects its difficulty
- Presenting the content at an appropriate pace
- In contrast to curriculum learning which ranks examples with respect to a target hypothesis, teacher-student methods uses current hypothesis of the learner
- Methods like hard data mining and boosting prefer more difficult examples with respect to the current hypothesis
Methods
- Curriculum learning attempts to leverage prior information about the difficulty of training examples
- Scoring function: specifies the difficulty of any given example
- Transfer scoring: confidence score from classifier trained on top of pre-trained ImageNet features
- Self-taught scoring: confidence score from network trained using vanilla method
- Pacing function: determines the sequence of data subsets from which batches of examples are sampled – limit to monotonically increasing staircase functions
- Fixed exponential pacing: fixed step length, exponentially increasing at each step
- Varied exponential pacing: varying step length
- Single step pacing: single step staircase
Results
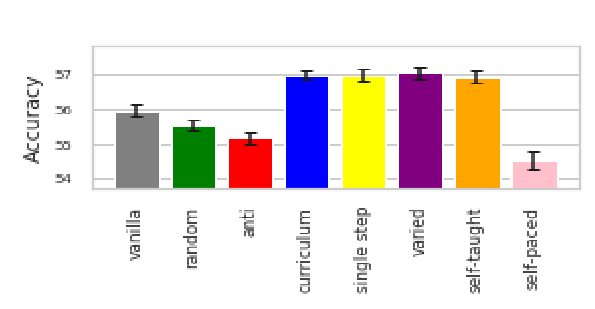
- Baselines:
- Anti-curriculum: training examples are sorted in descedning order of difficulty
- Random curriculum: uses random scoring function
- Vanilla: uniformly sample mini-batches from whole dataset
- Case 1: moderate sized network trained on 5 classes (same super-class) from CIFAR-100
- Curriculum learning (transfer scoring, fixed exponential pacing) learns faster and better than the other methods
- Anti-curriculum is the worst, with random and vanilla in the mdidle
- Self-taught scoring has simliar performance to transfer scoring, but self-paced learning (using current hypothesis) reduces the test accuracy
- Single step pacing does as well as fixed exponential pacing, which is surprising since it only uses a small fraction of the easiest examples
- Advantage of curriculum learning is larger when task is harder, based on using different super-classes
- Case 2 and 3: moderate sized network on CIFAR-10 and CIFAR-100
- Like before, curriculum learning has a larger effect for CIFAR-100
- Case 4 and 5: large VGG-based network on CIFAR-10 and CIFAR-100
- Curriculum learning (transfer scoring, varied exponential pacing) gives smaller benefit, possibly because of larger network
- Case 6: moderate sized network on 7 classes of cats from ImageNet
Conclusion
- They don’t really show any empirical differences between the different scoring and pacing functions, and the empirical benefit of curriculum learning has already been shown in various contexts
- The datasets they use are all very simple, ranging from 3k-60k images and 5-100 classes