Hierarchical Relational Inference
Stanic et al., 2020
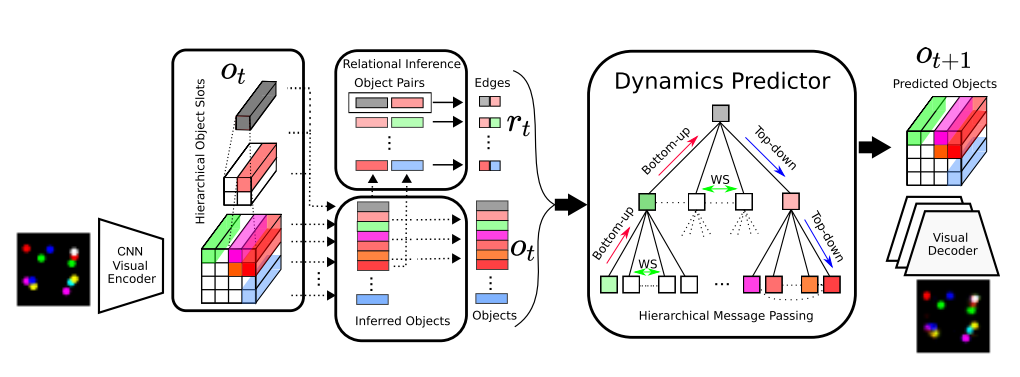 Source: Stanic et al., 2020
Source: Stanic et al., 2020Summary
- Tackles the problem of physical common sense by learning about objects and their dynamics
- Models objects as hierarchies of parts with relations, learned directly from raw visual inputs
- Improves over models that don’t explicity distinguish multiples levels of abstraction
- Links: [ website ] [ pdf ]
Background
- Real world objects vary greatly in terms of their physical properties, locally behaving somewhat independantly while globaly acting as a whole
- Suggests that a hierarchical representation could be useful
- Hierarchical Relational Inference (HRI) is an end-to-end approach for learning hierarchical object representations and their relations from raw visual input
- Previous appraoches that learn from videos do not use part-based object representations
- Extends Neural Relational Inference (NRI) in two ways:
- Use of hierarchical interaction graphs
- Learns from images, instead of relying on access to object states
Methods
- Visual Encoder: Produces hierarchical representations of objects, grounded on input image
- Partitions CNN feature maps according to their spatial coordinates
- Constructs 3-level hierarchy, which results in 16 leaf objects, 4 intermediate objects, and 1 root object
- Relational Inference Module: Infers pairwise relationships between objects and their parts
- Learns explicit relations, allowing for prior about overall connectivity of interaction graph and differentiation between different relation types
- Infers edges at each time step based on ten most recent object states
- Dynamics Predictor: Performs hierarchical message-passing on interaction graph
- Three phase (bottom-up, within-sibling, top-down) hierarchical message-passing
- Predicts change in object state
- Visual Decoder: Decodes updated object representations to image space
- SlotDec: Ensures compositionality by decoding objects separately followed by a summation
- ParDec: All object states are decoded together
- Trained in two stages:
- First, visual encoder and decoder on reconstruction task
- Second, relational module and dynamics predictor on prediction task
Results
- Datasets:
- State-springs: state trajectories of objects connected by springs in a hierarchical structure
- Visual-springs: rendered videos of state-springs
- Human3.6M: rendered joints of moving human bodies
- KTH: videos of moving humans
- Baselines:
- NRI: does not use hierarchical interaction graph
- LSTM: lacks relational inference
- Significant increases in performance on state-spings from LSTM to NRI to HRI
- NRI-GT, using ground-truth interaction graph, is much better than NRI, but HRI-GT is the same as HRI
- There is still a gap between HRI-GT and NRI-GT, indicating the benefit of the hierarchical representation
- ParDec does a bit better, possibly due to visual occlusions
- On KTH, NRI is only slightly worse than HRI
Conclusion
- The main experiments where HRI performs better are on the spring datasets, where there is a strong influence of hierarchical interactions
- Results on the real world dataset, KTH, is not very conclusive
- Hierarchical Relational Inference (HRI) learns hierarchical object representations and their relations directly from raw visual inputs, but is evaluated against limited baselines on simple datasets