Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
Grill et al., 2020
 Source: Grill et al., 2020
Source: Grill et al., 2020Summary
- Proposes Bootstrap Your Own Latent (BYOL), an approach for self-supervised visual representation learning
- Train an online network to predict the target network representation of the same image under a different augmented view
- Achieves SotA for self-supervised, semi-supervised, and transfer learning when trained on ImageNet, without the use of negative pairs
- More robust to changes in batch size and set of image augmentations compared to previous contrastive learning approaches
- Links: [ website ] [ pdf ]
Background
- Contrastive methods, which achieve SotA performance on the difficult problem of learning visual representations without human supervision, generally require careful treatment of negative pairs
- Unclear if using negative pairs is necessary
- Prior self-supervised learning work, MuCo, also uses moving average network, but for maintaining consistent representations of negative pairs drawn from a memory bank
- Many successful self-supervised approaches build off of the cross-view prediction framework, generally learning representations by predicting different views of the same image from one another
- Doing this prediction directly in representation space can lead to collapsed representations, e.g. a constant representation across all views
- Contrastive methods reframe this prediction problem as discrimination, but require comparing with appropriate negative examples that make the discrimination task challenging
Methods
- BYOL’s goal is to learn a (visual) representation that can be used for downstream tasks
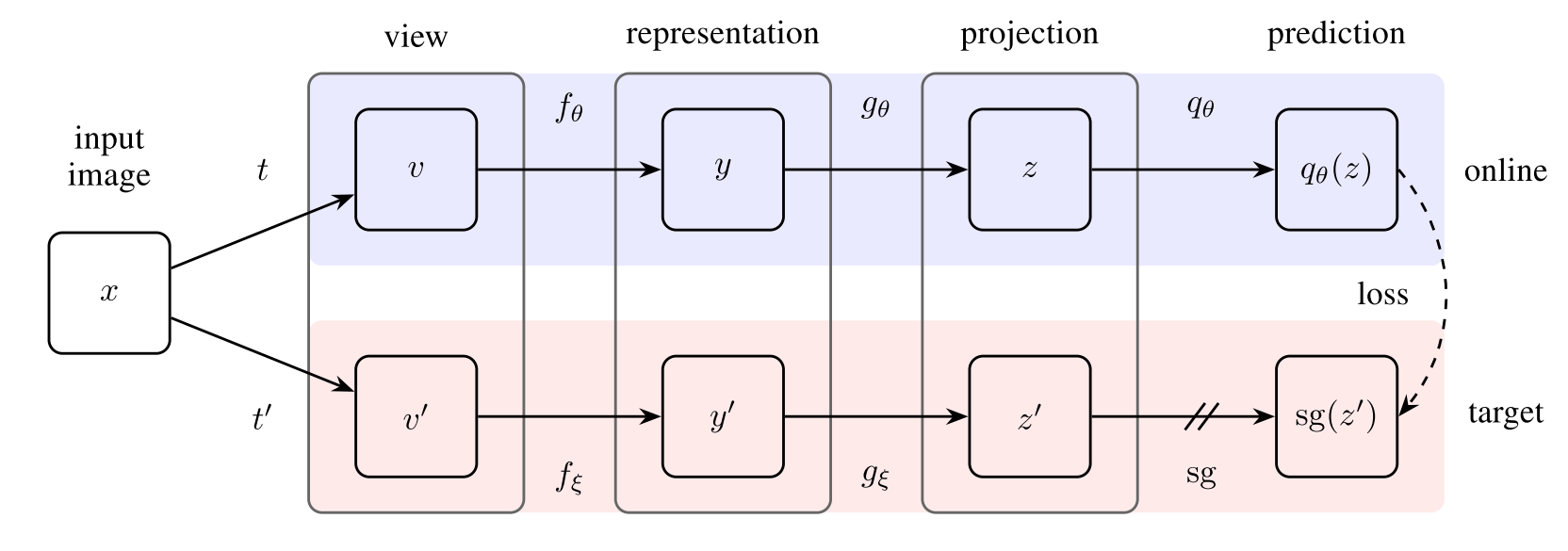
- Uses two neural networks:
- Online network: defined by a set of weights $\theta$ and composed of an encoder, a projector, and a predictor
- Target network: same architecture as the online network, but defined by a different set of weights $\xi$, which are an exponential moving average of the online network parameters $\theta$
- The online network is optimized by minimizing the MSE between the normalized predictions and target projections
- The prediction is obtained from the final output of the online network
- The target projection is obtained from the projector of the target network
- The networks are applied to two different augmented views of the same image
Results
- With standard ResNet-50 (1x) BYOL obtains 74.3% top-1 accuracy for linear evaluation on ImageNet
- ResNet-50 (4x) is only 0.3% below the best supervised baseline for the same architecture
- On other classification datasets, BYOL outperforms Supervised-IN baseline on 7 out of 12 benchmarks
- BYOL outperforms ImageNet supervised baseline on transfer to other vision tasks on different datasets (e.g. VOC semantic segmentation, NYUv2 depth estimation)
- Since BYOL does not use negative examples, it is more robust to smaller batch sizes compared to SimCLR, with stable performance over batch sizes from 256 to 4096
- BYOL is also incentivized to keep all information captured by the target representation, which makes it more robust to the choice of image augmentations, however there is still a significant drop in performance when removing augmentations
- Target network is beneficial by itself for its stabilization effect
Conclusion
- BYOL remains dependent on existing augmentations that are specific to vision
- Automating search for augmentations for other modalities would be important for generalizing BYOL
- The lack of negative examples makes this approach quite appealing