Are we done with ImageNet?
Beyer et al., 2020
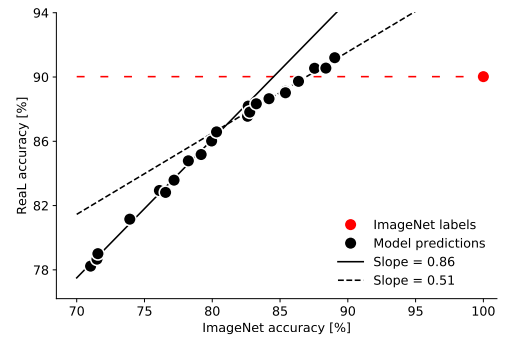 Source: Beyer et al., 2020
Source: Beyer et al., 2020Summary
- Addresses whether recent progress on ImageNet continues to represent meaningful generalization
- Assess the performance of ImageNet classifiers on new human annotations of the validation set
- Gains on new labels is substantially smaller compared to original labels
- New annotation procedure largely remedies errors in original labels
- Links: [ website ] [ pdf ]
Background
- ImageNet has long been the standard benchmark for computer vision, with its scale and difficulty resulting in general visual representations that can be used for various downstream tasks
- There are a few previous studies that identified various sources of noise and bias in ImageNet, but do not address how they might affect model accuracies
- There is also concurrent work by Tsipras et al. with slightly differing analyis and conclusions
Methods
- What’s wrong with ImageNet labels?
- Single label per image: problematic when there are mulitple objects in a single image
- Overly restrictive label proposals: particular label can seem reasonable in isolation, but less suitable when considering the complete set of all categories
- Arbitrary class distinctions: essentially duplicate labels exist (e.g. “laptop” vs. “notebook”, “sunglasses” vs. “sunglass”)
- Relabeling the ImageNet validation set
- Collect proposals using set of 19 models, in addition to original label
- Human evaluation of propsed labels, whether or not label is present in image or unsure
- ReaL accuracy: model’s top-1 prediction is considered correct if included in set of Reassessed Labels
Results
- Regressing ImageNet accuracy onto ReaL accuracy results in strong linear relationship with lower slope for higher performing models
- Original ImageNet labels obtain 90% ReaL accuracy, which is already surpassed by a few models – indicating possible diminishing utility of ImageNet accuracy as an evaluation metric
- Models’ second and third prediction’s accuracies are correlated with their top prediction’s ReaL accuracy
- Looking images with multiple objects or with synonym labels shows that top performing models on ImageNet are overfitting to the biases in the labeling procedure
- Evaluation using ReaL labels decreases the number false negatives, but it’s still non-zero
- Using a training objective that allows multiple non-exclusive predictions for a single image improves both ImageNet and ReaL accuracy
- Use top perfoming models, which surpass original ImageNet labels on predicting human preferences, to filter noise in original labels also helps performance, especially for longer trainings
- Combining this with the new training objective results in minor improvements
Conclusion
- Addressing the limitations of the original ImageNet labels seems to provide an improved evaluation metric that better aligns with human judgements
- More generally, it is important not to focus solely on a single metric and continuously verify that the metrics used actually serve as a good proxy
- Unclear whether modified training setups decrease the amount of “clear mistakes”