Learning the Predictability of the Future
Suris et al., 2021
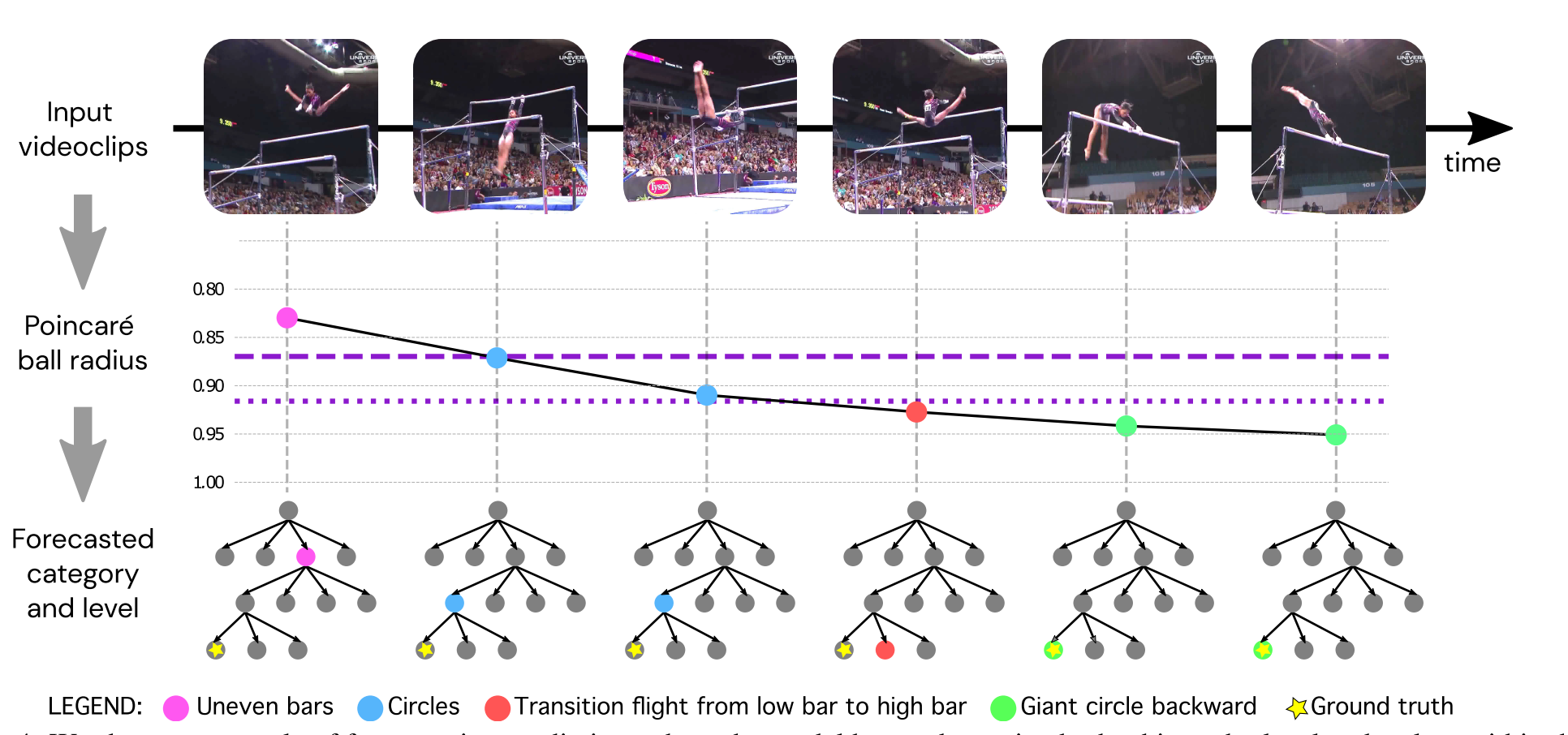 Source: Suris et al., 2021
Source: Suris et al., 2021Summary
- Learning from unlabeled video what is predictable in the future
- Build predictive model in hyperbolic space, which naturally encodes hierarchical structure
- Automatically selects higher level of abstraction when uncertain
- Emergence of action hierarchies in learned representations
- Links: [ website ] [ pdf ]
Background
- Future predction has been a core problem in computer vision
- How to figure out what to predict? e.g. pixels, activities, etc.
- Most methods do not have adaptive representations and objectives that adapt to the uncertainties in video
- Methods that represent uncertainty with stochastic latent inputs are compatible with proposed method
- Proposed method learns from data which features are predictable, instead of commiting up front to a level of abstraction to predict
- Jointly learns action hierarchy and correct level of abstraction within this hierarchy
- Hyperbolic space can be seen as the continuous analog of a tree, resulting in a hierarchy when representations are embedded in this space
Methods
- Learn a video representation that is predictive of the future
- Predict a latent representation of the future, not pixels
- Use Poincare ball model to define the distance between predicted and observed representation
- Trained using contrastive loss with hyperbolic distance as similarity measure, negative examples from other videos
- Contrastive loss to prevent trivial representations that result when directly regressing latent representations
- In hyperbolic space, mean of two embeddings is a parent embedding (i.e. higher level abstraction)
- Trained using contrastive loss with hyperbolic distance as similarity measure, negative examples from other videos
- Train classifier on top of learned representations
- Use hyperbolic multiclass logistic regression, since input representation is hyperbolic not Euclidean
- Use standard (Euclidean) ResNet encoder, GRU, and MLP with a projection to hyperbolic space
Results
- After learning representation from unlabeled videos, transfer to target domain using smaller, labeled dataset
- Fine-tune representations then train supervised linear classifier
- Datasets:
- Sports Videos: Self-supervise on Kinetics-600 (600 human action classes, 500,000 videos) and evaluate on FineGym (gymnastic videos with three-level hierarchical action labels)
- Movies: Self-supervise on MovieNet (1,100 movies, 758,000 key frames) and evaluate on Hollywood2 (two-level action hierarchy)
- Metrics:
- Accuracy: accuracy on leaf classes
- Bottom-up hierarchical accuracy: partially correct if incorrect at leaf level but correct at higher levels (50% decay per level as you go up)
- Top-down hierarchical accuracy: 50% decay as you go down
- Early action recognition: classify actions that have started but not finished
- Hyperbolic representations outperform Euclidean, with a larger gap when embedding dimension is smaller
- Future action prediction: predict actions before they start, given past context
- Evidence for compactness of hierarchical representations is reversed
Conclusion
- Not sure how to interpret future action prediction results since there’s no ground truth as to which level to predict when
- Datasets don’t really distinguish between hierarchy of actions in time versus abstraction
- Higher-level actions in the hierarchy are both longer in duration and more abstract (e.g. “human interaction” > “handshake”)
- Only applied to predicting actions, not lower-level object motions/dynamics
- Regardless of the actual results for this specific model, the idea of using hyperbolic embeddings for hierarchical representations is interesting