Learning Physical Graph Representations from Visual Scenes
Bear et al., 2020
 Source: Bear et al., 2020
Source: Bear et al., 2020Summary
- Attempts to address unsupervised learning of visual scene representations that can support scene segmentation tasks on complex real world images
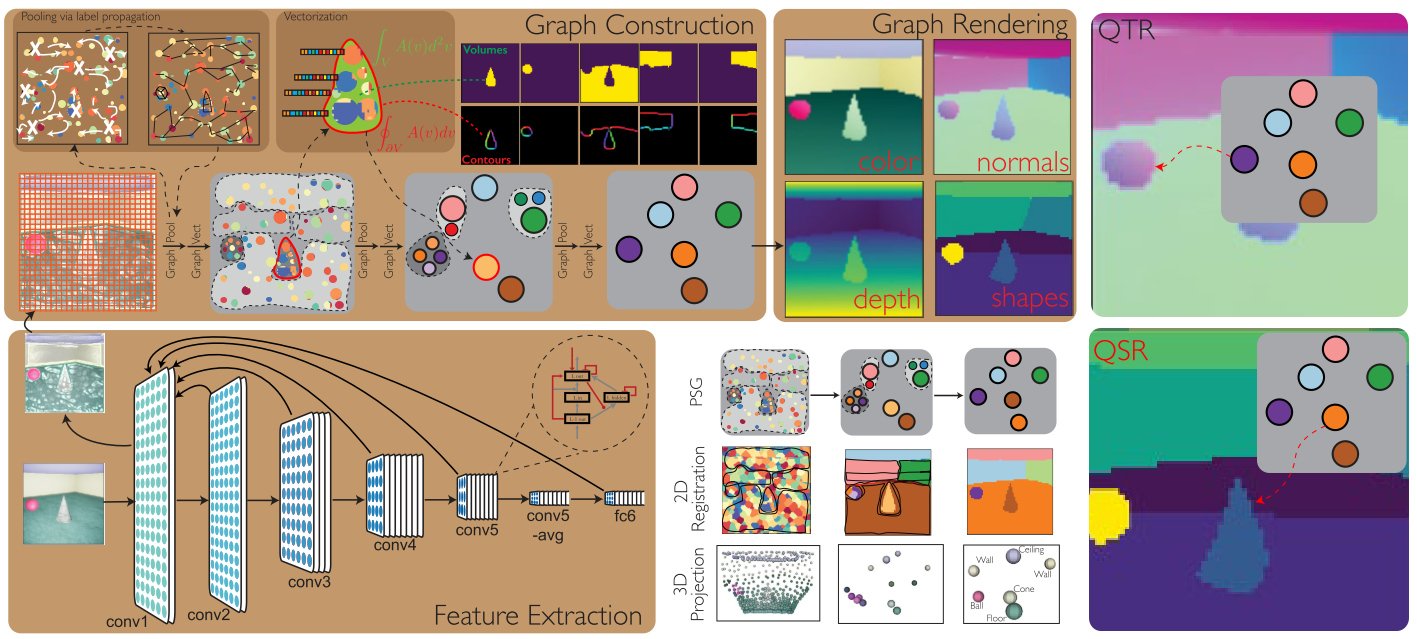
- Introduces “Physical Scene Graphs” (PSGs) that represent scenes as hierarchical graphs, with nodes that correspond to object parts at different scales and edges to physical connections between parts
- PSGNet, a novel architecture, outperforms alternative models and generalizes to unssen object types and scene arrangements
- Links: [ website ] [ pdf ]
Background
- While CNNs have been very successful at learning visual representations for tasks like object classification, their success has been limited on tasks that require a structured understanding of the visual scene
- Humans group visual scenes into object-centric representations many properties (e.g. object parts, poses, material properties, etc.) are explicitly available which support high-level planning and inference
- Recent work limited by architectural choices, learning from static images, or requiring detailed supervision (e.g. meshes)
- PSGs aims to geometrically rich and explicit enough to handle reasoning about complex shapes, but also flexible enough to learn from real world data through self-supervision
Methods
- “A PSG is a vector-labeled hierarchical graph whose nodes are registered to non-overlapping locations in a base spatial tensor”
- PSGNet takes in RGB movie inputs and outputs RGB reconstructions, depths, normals, object segmentation map, and next-frame RGB deltas for each next-frame
- Feature extraction:
- Generate feature map for input movie with a ConvRNN using features from first conv layer
- Concatenate one timestep backward differential to input
- Graph construction:
- Hierarchical sequence of learnable graph pooling and graph vectorization operations
- Graph pooling combines nodes from the previous layer into nodes of the new layer with corresponding child-parent edges
- Generate with-in layer edges by thresholding learnable affinity function on attribute vectors
- Affinity function based on perceptual grouping principles: feature, co-occurrence, motion-driven, and learned motion similarity
- Cluster nodes based on these edges without needing to specify the final number of groups
- Graph vectorization aggregates the attributes of the merged nodes, and transforms it into attributes for the new nodes
- Uses a combination of statistical summary functions
- Graph rendering:
- “Paint-by-numbers” using node attributes and spatial registration from graph construction
- Produce shapes from node attributes to generate output image
- Loss on each graph level and on rendered scene reconstructions
Results
- Datasets:
- Primitives: synthetic dataset of primitive shapes (e.g. spheres, cubes) in simple 3D room
- Playroom: synthetic dataset of complex shapes with realistic textures (e.g. animals, furniture, tools)
- Gibson: RGB-D interior scans of buildings on Stanford campus
- Metrics:
- mean intersection over union (mIoU)
- Recall: proportion of ground truth foreground objects whose IoU with predicted mask is > 0.5
- BoundF: average F1-score on ground truth and predicted boundary pixels of each segment
- Adjusted Rand Index (ARI)
- Baselines:
- MONet
- IODINE
- OP3
- Quickshift++: non-learned
- PSGNet outperforms baselines in static training, where models are given single RGB frames and trained with RGB reconstruction and depth and normal estimation, for Primitive and Gibson datasets
- PSGNet with motion-based grouping also outperforms other models for the Playroom dataset with four-frame movie inputs
Conclusion
- Segmentations are still not great especially for more complex scenes
- PSGs provide a flexible representation for encoding scenes