Entity Abstraction in Visual Model-Based Reinforcement Learning
Veerapaneni et al., 2019
 Source: Veerapaneni et al., 2019
Source: Veerapaneni et al., 2019Summary
- Presents a system for model-based reinforcement learning which learns from raw visual inputs
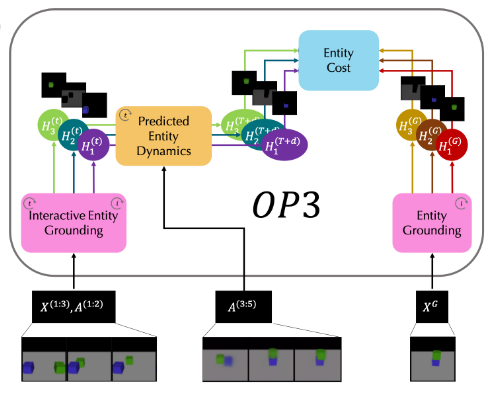
- Object-centric perception, prediction, and planning (OP3) uses a fully probabilistic entity-centric dynamic latent variable framework
- OP3 generalizes to novel block stacking configurations with more objects than observed in training
- Links: [ website ] [ pdf ]
Background
- Modeling scenes by modeling objects and the local processes that govern their interactions may provide benefits to generalization
- Some limitations of other approaches:
- assumes fixed number of entities
- does not constrain instances of the same entity to be modeled the same way
- require entity identities as additional inputs, or other related supervision
- do not model whole entities coherently
- cannot update entity representations with new observations
Methods
- Define probabilistic model where a set of latent variables represent the state of objects in the scene, in addition to random variables for the image observation and agent actions
- Approximate posterior predictive distribution of observations $d$ steps into the future by learning parameters of an approximate observation distribution, dynamics distrubution, and time-factorized recognition distrubution with variational inference
- Entity abstraction derived from assumption about symmetry, which reduces dynamic scene modeling to two steps:
- Model single entity and its interactions with entity-centric function
- Apply this function over each entity in the scene
- Observation Model: approximates the distrubution of the observation given the entities
- Implemented using a mixture model at each pixel, where the mixture components models the observation for each individual entity
- Dynamics Model: approximates the distribution of future entity latents given their current values and an action
- Combinatorially large space of object configurations and interactions
- Reduce the problem to modeling the effect on a single entity given the action and the entity’s interactions with the other entities
- Further reduce problem by enforcing pairwise interactions
- Solve variable binding by inferring parameters of the posterior distribution of entity variables given a sequence of interactions
- Decomposed into recognition distribution applied to each entity
- Iterative approach to break symmetry for dividing responsibility of modeling different objects in the scene
Results
- OP3 generalizes to solve block stacking (82%) while only being trained to predict how objects fall, 3x accuracy of SAVP (24%)
- Setup: In MuJoCo, block is raised in the air and model must predict steady-state effects of dropping it on surface with multiple objects
- Up to five objects in training, up to nine in testing
- Tested on constructing block tower specified by goal image
- Actions chosen based on greedy approach, assuming single actions are sufficient to move an object to its goal position
- Metrics: Accuracy based on checking that all blocks are within some tolerance of goal
- Baselines:
- SAVP: SOTA model for video prediction, does not process entities symmetrically
- O2P2: processes entities symmetrically, but requires object segmentations
- Setup: In MuJoCo, block is raised in the air and model must predict steady-state effects of dropping it on surface with multiple objects
- OP3 achieves 2.5x accuracy of SAVP on manipulating objects already present in the scene into goal position
- Setup: Initial scene contains all blocks needed
- Action space represents picking and dropping location, only sucessfully picks up if action intersects with block outline
- Moving objects out of place may be necessary, multi-step planning
- Setup: Initial scene contains all blocks needed
- Compared to IODINE applied to single frames, OP3 uses temporal information to better segment objects in real world videos of robotic arm moving deformable objects
Conclusion
- Symmetric modeling of entities provides clear benefits for generalization in block manipulation tasks in simulation
- Ability to continually update latent entity representations with new visual observations is another advantage
- Limited demonstration of planning and real world capabilities