Embodied Multimodal Multitask Learning
Chaplot et al., 2020
 Source: Chaplot et al., 2020
Source: Chaplot et al., 2020Summary
- Original version read was from arXiv [ pdf ]
- Deep RL has been successful in training visual navigational agents conditioned on language for multimodal tasks, e.g. semantic goal navigation and embodied question answering
- Propose a multitask model that can jointly learn these tasks
- Novel Dual-Attention unit to disentangle words and visual concepts
- Links: [ website ] [ pdf ]
Background
- Success in 3D games such as Doom and DeepmindLab, causing increased interset in training embodied agents, which interact with a 3D environment
- Receive first-person views
- Take navigational actions
- Interseted in specifying goals via language, versus say images or coordinates
- Allows generalization to new tasks without additional learning
- Natural medium for humans to communicate with autonomous agents
- Multimodal tasks require perception from raw pixels, grounding of words to visual attributes, reasoning, navigation, and question answering
- Multitask approach allows for knowledge to be shared across tasks and increases sample efficiency
- Most previous work focuses on single tasks or simpler environments, 2D or static.
Methods
- Consider autonomous agent interacting in episodic environment
- Receive textual input T at beginning of episode, specifying task
- State $ s_t=(I_t, T) $ at each time step $ t $, $ I_t $ is egocentric view
- Takes action a_t
- Learn policy $ \pi(a_t \vert s_t) $ to complete task
- Focus on two visually-grounded language navigation tasks ** Embodied Question Answering: Given a question, gather information from 3D environment to find answer ** Semantic Goal Navigation: Given language instruction, navigate to goal location
- ViZDoom-based environment
- Single room with 5 objects, randomized based on textual input
- 4 actions: forward, left, right, and answer
- Two difficulty settings
- Easy: Agent spawned in fixed location with all objects in FOV
- Hard: Agent and objects spawned randomly
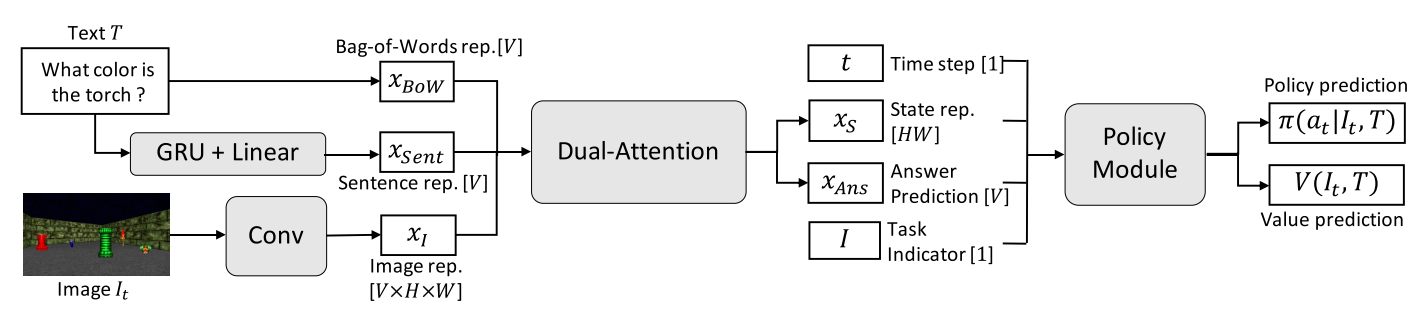
- BoW and sentence representation (GRU) for textual input, CNN for image
- Number of CNN channels equals size of vocabulary V
- Dual-Attention unit combines image and text representations and outputs complete state representation $ x_S $ and answer prediction $ x_{ans} $
- Gated attention between BoW and image features, then sum over channels and softmax to get spatial attention map
- Spatial attention between image features and spatial attention map
- Gated attention between spatial attention output and sentence features, then spatial summation and softmax for answer
- $ x_S, x_{ans} $, time step, and task indicator variable fed to policy to produce action
- Also tried spatial auxiliary task to detect object or attribute in each CNN output channel corresponding to the word
Results
- Train for 10 million (Easy) or 50 million frames (Hard)
- Baselines
- Image Only
- Text Only
- Concat (Hermmann et al. 2017, Misra et al. 2017): semantic goal navigation
- Gated-Attention (Chaplot et al. 2017): semantic goal navigation
- FiLM (Perez et al. 2017): question answering
- PACMAN (Das et al. 2017): question answering
- Proposed Dual-Attention model outperforms all baselines by a large margin, with and without the auxillary task
Conclusion
- Model is able to transfer knowledge of words across tasks
- How to deal with large vocabulary