Training data-efficient image transformers & distillation through attention
Touvron et al., 2020
 Source: Touvron et al., 2020
Source: Touvron et al., 2020Summary
- Visual transformers are generally trained with hundreds of millions of images, much larger than ImageNet
- Use distillation token in teacher-student strategy for training
- Produces competitive convolution-free transformer, training only on ImageNet
- Links: [ website ] [ pdf ]
Background
- While CNNs have been the main paradigm for computer vision, the success of transformers in NLP has motivated their application to vision tasks
- Hybrid architectures that combine CNNs and transformers exhibit competitive results
- However, fully convolution-free transformers (e.g. ViT) required extremely large supervised datasets (JFT-300M) – the authors note that transformers “do not generalize well when trained on insufficient amounts of data”
- Data-efficient image Transformers (DeiT) uses better training strategy to produce competitive results without convolution layers
Methods
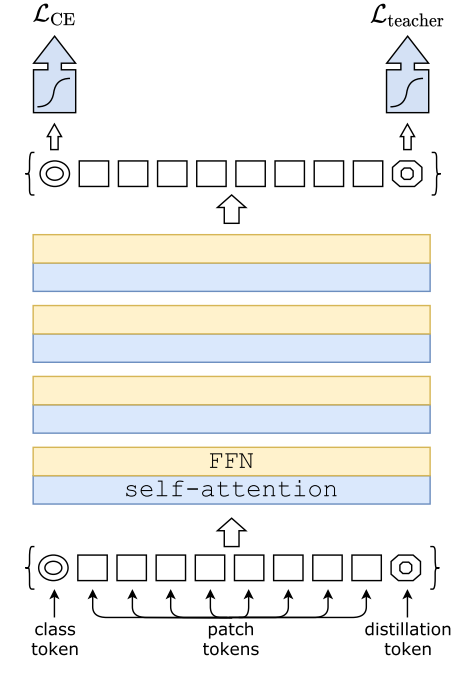
- Transformer block for images:
- Fixed-size RGB input image decomposed into a batch of N fixed-size patches
- Each patch is projected with a linear layer that conserves overall dimension
- Position information incorporated using postional embeddings
- Class token: trainable vector appended to the patch tokens as input, then projected with a linear layer to predict the class
- Only class token vector is used to predict the output class – spreads information between patch and class tokens
- Distillation through attention
- Soft distillation: minimize KL divergence between softmax of teacher and student
- Hard distillation: use hard decision of teacher as an additional true label
- Distillation token: used similarly as class tokens
- Allows student to learn from the output of the teacher, while remaining complementary to the class vector
- Note: Requires strong data augmentation, as usual for transformers
Results
- Using CNNs as teacher gives better performance (~1% top-1 accuracy) than using a transformer, probably due to the transfer of inductive biases through distillation
- Hard distillation outperforms soft distillation (~1.2%), with or without distillation tokens
- Distillation token provides small benefit (~0.4%) for initial training, but diminished when fine-tuning at higher resolutions
- Learned class and distillation tokens converge to different vectors (0.06 cosine similarity)
- Without distillation, performance saturates in longer training schedules
- DeiT performs similarly to CNNs when transferring to other image classification tasks
Conclusion
- Seems like DeiT without distillation actually does pretty well (81.8% ImageNet top-1)
- Hard distillation provides a slight benefit and distillation tokens have a marginal effect
- Not sure why DeiT-B without distillation outperforms ViT-B by so much
- Potential for convolution-free visual transformers, with further optimization, to replace CNNs?
- Using CNNs as teacher for visual transformers also promising