Control What You Can: Intrinsically Motivated Task-Planning Agent
Blaes et al., 2019
 Source: Blaes et al., 2019
Source: Blaes et al., 2019Summary
- Addresses how to make an agent learn efficiently to control its environment with minimal external reward
- Proposes method that combines task-level planning with intrinsic motivation
- Improved performance compared to intrinsically motivated, non-hierarchical and hierarchical baselines in synthetic and robotic manipulation environments
- Links: [ website ] [ pdf ]
Background
- Babies seemingly conduct experiments on the world and analyze the statistics of their observations to form an understanding of their world
- Undirected “play” behavior is also commonly observed, which can be viewed as trying to gain control
- One example is learning to use tools to increase what is controllable
Methods
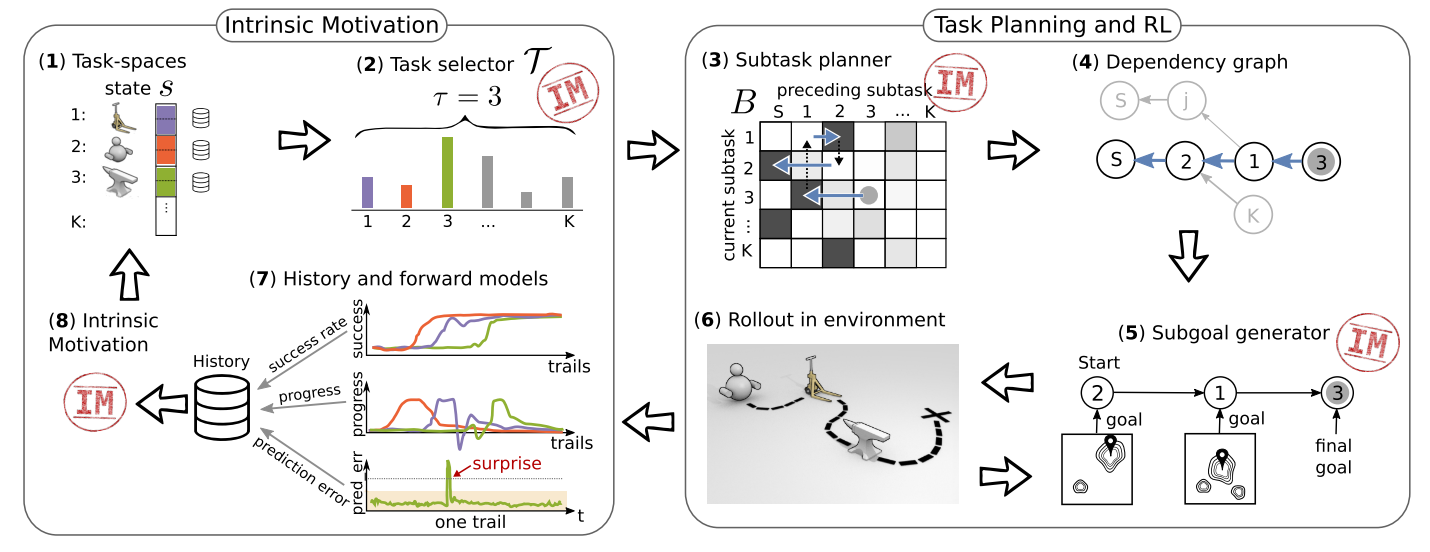
- Assume observable state space is partitioned into potentially controllable components (goal spaces), manipulation of these components is formulated as tasks
- The perception problem of constructing the goal spaces from sensor modalities (e.g.image data) is not considered
- Control What You Can (CWYC) approach:
- Tasks defined by components of the state space
- Task selector, implemented as multi-armed bandit, selects (final) tasks that maximizes expected learning progress
- $\epsilon$-greedy task planner computes sub-task sequence form learned task graph, which captures how quickly a sub-task can be solved when another sub-task is performed directly before
- Sub-goal generator, implemented with relational attention networks, create goals in the current sub-task to maximize success in subsequent task
- Goal-conditioned task-specific low-level policies control the agent (SAC or DDPG+HER)
- Training results (success rate, progress, surprise) is stored in a history buffer
- Intrisic motivation module computes rewards for task selector, task planner, and sub-goal generator
- Learning progress is defined as the time derivative of the success rate, with success defined as reaching a goal state within some tolerance
- Use thresholded prediction error to bootstrap early learning in task selector
Results
- Environments:
- Synthetic environment: 2-DOF point mass agent with several objects in an enclosed area, implemented in MuJoCo, continuous state and action spaces
- Contains four objects: tool, heavy object, unreliable (50%) object, and random object
- Arena is large so random encounters are unlikely
- Robotic manipulation: robotic arm with gripper (3+1 DOF) in front of table with hook and box at random, out of reach locations, needs to use hook
- Goal spaces defined as: reaching target position with gipper, manipulating the hook, manipulating the box
- Objects relations are less obvious, but random manipulations are more frequent
- Synthetic environment: 2-DOF point mass agent with several objects in an enclosed area, implemented in MuJoCo, continuous state and action spaces
- Metrics:
- Success rate: overall success of reaching random goal in each task space
- Baselines:
- Hierarchial reinforcement learning with off-policy correction (HIRO): sovles each task independently
- Intrisic curiosity module with surprise (ICM-S)
- Intrisic curiosity module with raw prediction error (ICM-E)
- SAC: low-level controller
- DDPG+HER: low-level controller
- CWYC w oracle: oracle task planner and sub-goal generator
- In synthetic environment, methods that treat each task independently (SAC, ICM-(S/E), HIRO) can only solve locomotion, while CWYC solves all three tasks: locomotion, tool use, and heavy object manipulation
- Task selector learns curriculum order of locomotion, tool, heavy object, then finally 50% object
- In the robotic manipulation, only CWYC and DDPG+HER can solve all three tasks
- CWYC has slightly better sample complexity compared to DDPG+HER
- Demonstrates that suprise (e.g. unintentionally hitting the tool) helps identify funnel states with ~30 positive samples
Conclusion
- The success of DDPG+HER in the robotic arm environment makes the results less convincing, this baseline was not used in the synthetic environment
- State space is relatively low-dimensional and goals are only 2-D, $(x, y)$
- Parameterization of sub-goal generator seems particularly suited for the specific context
- Prior information encoded in task/state space limits its practical use