Automatic Goal Generation for Reinforcement Learning Agents
Florensa et al., 2018
 Source: Florensa et al., 2018
Source: Florensa et al., 2018Summary
- Curriculum learning applied to RL context
- Generates target goals during training using GAN to ensure goals are of ‘intermediate’ difficulty
- Experiments with Ant on plane and in maze
- Links: [ website ] [ pdf ]
Background
- Most of the recent successes in RL are in settings where the agent is trained to optimize a single reward function for a single task.
- Want to create agents that can perform a variety of tasks
- Maximize average success rate over all possible goals
- Graves et al., 2017 focuses on supervised setting, can’t apply learning progres signals to RL setting with sparse rewards
Methods
- Define goal-parametrized reward function that indicates whether the agent reaches the goal within T steps
- For a given policy, expected return for the goal is the probability of success
- Captures the property that it may be difficult to tell if agent is getting closer to goal, but easy to tell if it’s achieved
- Overall objective is to find a policy that maximizes the average probability of success over goals sampled from a (test) goal distribution
- First, label set of goals as intermediate difficulty if expected reward for the goal with the current policy is between some min and max value (e.g. 0.1-0.9)
- Second, generate new goals of intermediate difficulty using a GAN
- Modified to also be trained on “negative examples”
- Update policy based on these goals, and repeat
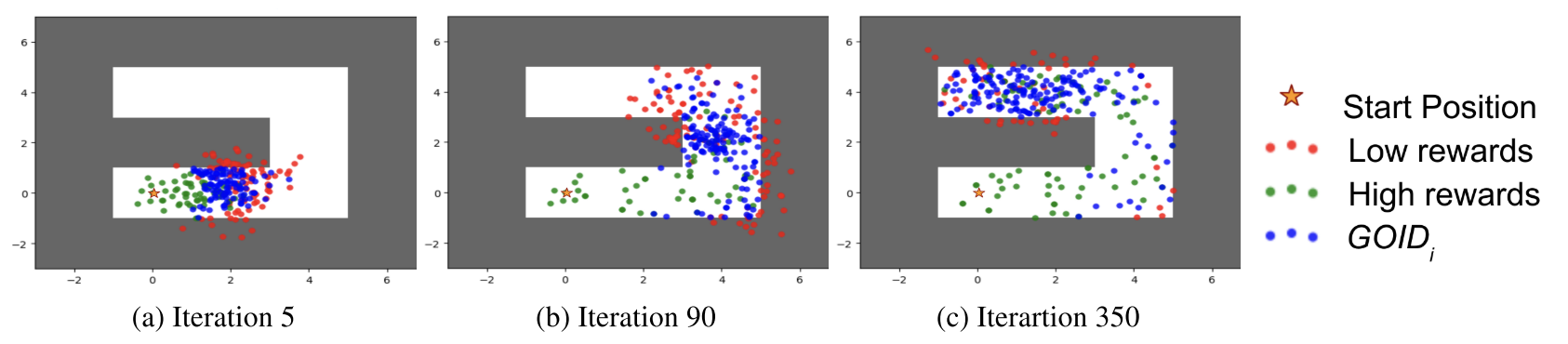
Results
- Test on ant on plane and in maze, where goals are $(x,y)$ position
- Increased efficiency compared to uniform sampling, with and without l2 distance reward. Slightly better than asymetirc self-play and SAGG-RIAC in maze
- About 20% of generated goals are intermediate difficulty, even as policy improves
- Growing ring of goals in Free Ant
- Clear benefit of generating appropriate goals when feasible states are a lower-dimensional subset of the full state space
Conclusion
- Training the GAN on all previous goals actually doesn’t do that bad, for 2D
- No novelty based baselines, but using coverage as metric