Attention Is All You Need
Vaswani et al., 2017
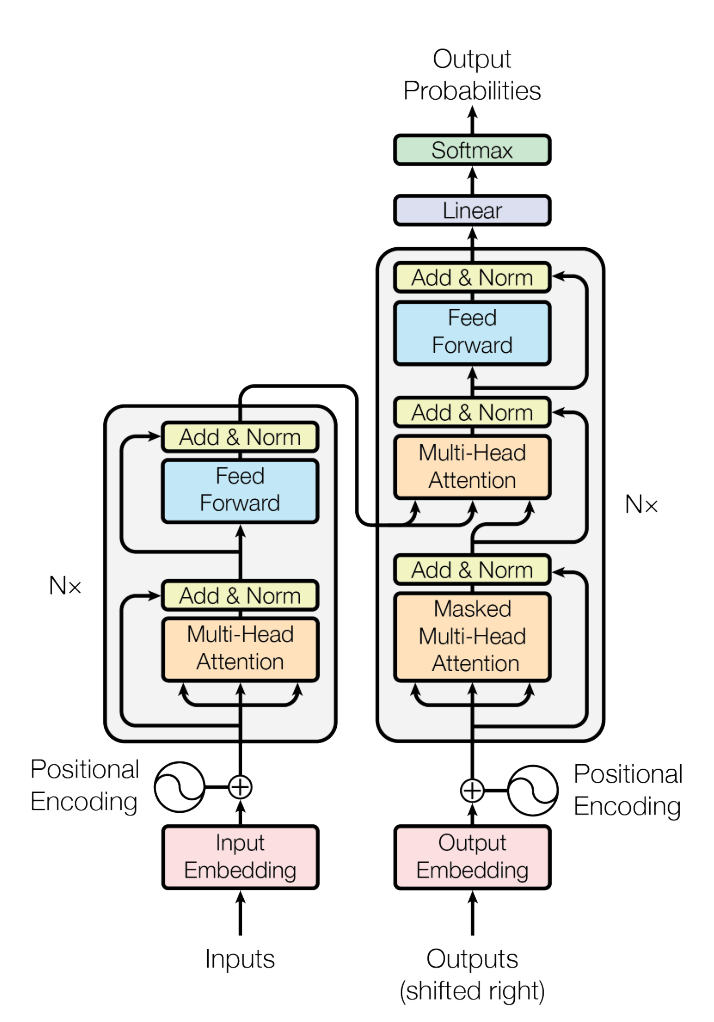 Source: Vaswani et al., 2017
Source: Vaswani et al., 2017Summary
- Proposes a sequence transduction model based soley on attention mechanisms, instead of complex recurrent or convolutional neural networks
- Outperforms other models on machine translation tasks while being computationally cheaper
- Links: [ website ] [ pdf ]
Background
- RNNs have been firmly established as the SotA approaches for sequence modeling and transduction problems (e.g. language modeling, machine translation)
- RNNs factor computation along symbol positions, which precludes parallelization within training examples due to its inherently sequential nature
- The Transformer model relies entirely on attention mechanisms instead of recurrence to model dependencies between input and output
- Attention mechanisms allow modeling of dependencies regardless of the distance in the sequence
Methods
- Encoder: Maps an input sequence of symbols to a sequence of continuous representations
- Composed of a stack of $N$ identical layers, each with two sub-layers: multi-head self-attention and position-wise fully connected feed-forward network
- Residual connection around each of the sub-layers, followed by layer normalization
- All sub-layers in the model and the embedding layers have the same output dimension
- Decoder: Generates output sequence of symbols one element at a time
- Also composed of a stack of $N$ identical layers, each with three sub-layers
- Additional multi-head attention over output of the encoder stack
- Modify self-attention sub-layer to prevent positions from attending to subsequent positions
- Also composed of a stack of $N$ identical layers, each with three sub-layers
- Multi-head Attention: Project queries, keys, and values $h$ times with different, learned linear projections
- Perform attention function in parallel, concatenate resulting output values, and then apply a final projection
- Enables jointly attending to different subspaces at different positions
- Position-wise Feed-forward Networks: FCN applied to each position separately and identically
- Positional Encoding: Inject information about relative (or absolute) position of the tokens in the sequence
- Sum the positional encodings with input embeddings
- Fixed positional encoding using sine and cosine functions of different frequencies
Results
- Compared to recurrent and convolutional layers, self-attention has:
- Better computational complexity when sequence length is smaller than representation dimensionality, which is generally the case
- Similar complexity of sequential operations to CNNs ($O(1)$), better than RNNs ($O(n)$)
- Shorter maximum path length than CNNs ($O(\log_k(n)$) and RNNs ($O(n)$)
- Outperforms SotA single models, achieving a BLEU score of 41 on WMT 2014 English-to-French translation task, with a quarter of the training cost
- Model variations on English-to-German translation task:
- Performance drops off with too few or too many attention heads
- Reducing attention key dimensionality hurts performance, indicates more sophisticated compatibility function may be beneficial
- Bigger models are better
- Dropout is helpful for reducing over-fitting
- Learned positional embeddings perform basically identically to fixed positional encoding
- Shows generalization to other tasks by performing well on English constituency parsing compared to previous models, especially other RNN seq-to-seq models
Conclusion
- Presents the Transformer, a sequence transduction model that replaces recurrent layers and relies entirely on attention mechanisms
- Offers many benefits over RNN models
- Future work includes investigating restricted attention mechanisms to efficiently handle large inputs and outputs